Load Balancing & ECMP
You've picked a topology. Now: when the fabric has N equal-cost paths and a packet shows up at a leaf, how does the leaf decide which path to use? That's the LB strategy — and it's where most AI fabrics live or die.
- Recite the four LB tiers — SLB → DLB → GLB → TELB — and what each one adds.
- Explain why ECMP works for web traffic and breaks on AI — in one paragraph.
- Set the cheap fix every cluster should have (
NCCL_IB_QPS_PER_CONNECTION=4). - Pick the right tier for your fabric scale + silicon — and know when each one stops being enough.
This page is the prose tutorial. The image below is the reference card. The Load Balancing Playground is the hands-on simulator. Use all three.
The whole page on one card
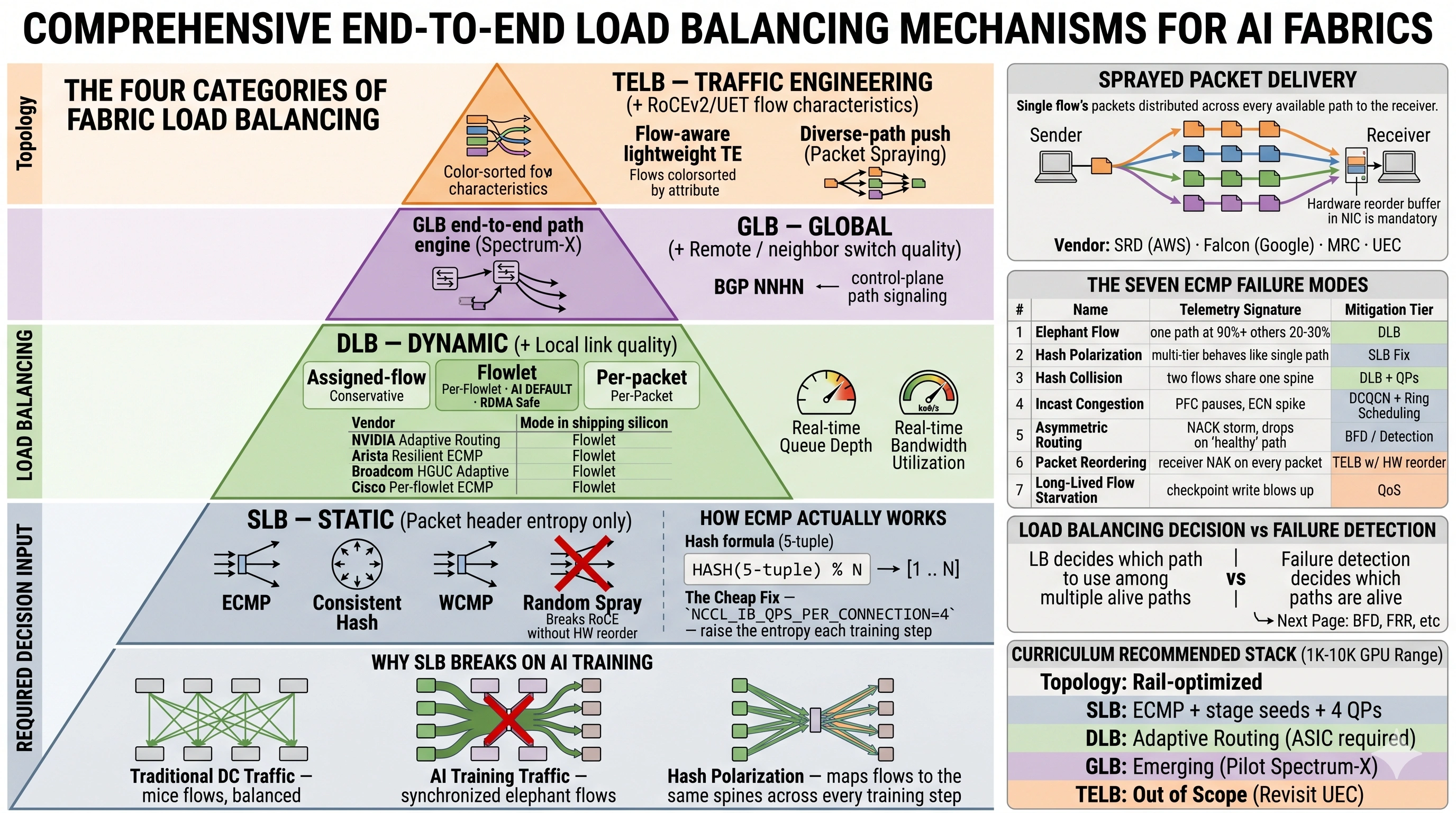
The pyramid is the four LB tiers. The right column is the seven ECMP failure modes + the LB-vs-failure-detection distinction + what this curriculum recommends. The rest of this page is the learning journey through it.
1. The four LB tiers — the hierarchy
Each tier adds one new input the tier below couldn't see. That's the whole organizing principle.

Read this top-down:
- SLB is what every Clos fabric ships with by default. Hash 5-tuple, modulo
N, done. Works for web traffic; breaks on AI. - DLB is the practical upgrade for AI fabrics. The switch ASIC tracks its own queue depth and reassigns flows at flowlet boundaries. The green Flowlet box is the default mode every shipping vendor uses.
- GLB adds visibility beyond the local switch — what's the downstream leaf's queue look like? Emerging at hyperscale (Spectrum-X, BGP NNHN).
- TELB rebuilds the transport itself to spray packets across every available path. Hardware reorder buffer at the receiver. Shipping in production at hyperscale (MRC at OpenAI), still a year out for everyone else (UEC).
The rest of this page walks the tiers from bottom to top — what each adds, what each costs.
2. The default — ECMP
ECMP is the LB primitive every Clos fabric ships with. It's an SLB technique (the lowest tier): the only input is packet header entropy.
ecmp_index = HASH(src_IP, dst_IP, src_port, dst_port, proto) % N
CRC-32 or vendor XOR variant. Same 5-tuple → same index → same uplink, for the entire flow. The property is load-bearing: it keeps TCP / RoCE packets in order without per-flow state in the switch.
On a traditional DC, this works almost by accident. The traffic mix has enough entropy that the modulo distribution flattens out. Try this in the playground — pick ECMP + Web traffic, watch all four spines pull ~25% of the load.
3. Why ECMP breaks on AI training
You already know from 3.1 that AI training traffic is synchronized, elephant-sized, and lockstep. Here's the specific mechanism that turns those three properties into an ECMP failure.
RoCE v2 collapses 4 of the 5 hash fields. proto = UDP (constant), dst port = 4791 (constant), src/dst IPs are narrow per-rail ranges. The entire LB decision lives on UDP source port. If the NIC picks it deterministically per QP (the default on many drivers), the same gradient flow hashes to the same spine every training step, for the entire run — hours, sometimes weeks.
Combine that with synchronized elephants from 3.1: every GPU's AllReduce flow ends up on the same deterministic spine. Six of eight elephants land on Spine 0. The other three spines sit idle for the entire job.

Try this in the playground — same ECMP, flip the traffic toggle to "AI training." Six of eight elephants land on Spine 0. Throughput collapses to ~30%.
Trusting plain SLB / ECMP as your only LB strategy on an AI fabric. The hash will polarize, the elephants will collide, your AllReduce will run at 30–50% of line rate forever — with no obvious error in any log. SLB needs help. Move up the tiers.
4. The cheap fix — NCCL_IB_QPS_PER_CONNECTION=4
Before any ASIC purchase, set this on every cluster. It tells NCCL to open 4 Queue Pairs per peer-pair. Each QP picks a different UDP source port → different hash → different spine. 4× the SLB entropy.
It doesn't fix polarization or collision; it raises the bar enough that hash collisions stop dominating. Free.
5. Move up the tiers — DLB, GLB, TELB
DLB — Dynamic. Adds local link quality (egress queue depth, bandwidth). The switch picks paths to less-loaded queues and reassigns at flowlet boundaries (>500 µs gaps, RDMA-safe). Reacts in ~1 ms via queue telemetry. The image's vendor matrix lists the ASICs: NVIDIA Spectrum-3+, Arista Tomahawk-4+, Broadcom Tomahawk-4+, Cisco Silicon One G200+ — all flowlet mode. DLB is the practical default at 1K–10K GPUs. Try it in the playground — pick Flowlet DLB + AI traffic, watch the load redistribute live.
GLB — Global. Adds remote / neighbor switch quality. Two shipping patterns: NVIDIA Spectrum-X's end-to-end path engine, and BGP NNHN for two-hop path advertisement. GLB pays off when DLB's local view is provably wrong — typically 5K–20K GPU fabrics where downstream incast is the dominant pattern.
TELB — Traffic Engineering. Adds RoCE v2 / UET flow characteristics — the fabric understands the application. Two families:
- Flow-aware lightweight TE — per-flow path computation respecting QP characteristics
- Packet spraying (diverse-path push) — every packet picks its own path, receiver's HW reorder buffer reassembles. AWS SRD (Nitro NIC), Google Falcon (proprietary), MRC (already in production at OpenAI's GB200 fleet — Oracle Abilene, Microsoft Fairwater, OCP-spec), UEC (open standard, target shipping 2025–26)
TELB needs new NIC silicon. You don't retrofit packet spraying onto a ConnectX-7. For the next 18–24 months, TELB lives at hyperscale; everyone else should plan for it but run DLB today.
6. The seven failure modes — at a glance
The image's middle-right table lists all seven with telemetry signatures and which tier mitigates each. Memorize that table — every "training is slow" ticket is one of these. Quick recap of the most common three:
- Elephant Flow — one spine at 90%, others at 20%. Mitigation: DLB.
- Hash Polarization — multi-tier Clos behaves like single path. Mitigation: per-stage hash seeds in SLB.
- Hash Collision — two flows accidentally share one spine. Mitigation: DLB + more QPs.
A working AI fabric mitigates all seven by stacking techniques across tiers, not picking one.
7. Load balancing is not failure detection
The image's bottom-right callout makes the distinction sharp. LB decides which path to use among multiple alive paths. Failure detection decides which paths are alive. Different problems, different mechanisms, different pages.
BFD, BGP convergence, IP FRR — all failure detection. None of them spread traffic; they react to dead paths. Separate problem class.
8. What to pick (1K–10K GPU range)
Repeated from the image's bottom-right box, here's the curriculum's recommended stack:
- Topology: rail-optimized — see 3.3 Rail-Optimized Topology
- SLB: ECMP + per-stage hash seeds +
NCCL_IB_QPS_PER_CONNECTION=4 - DLB: adaptive routing on every leaf-spine adjacency. Pay for the ASIC tier — the throughput gain pays back inside a quarter.
- GLB: emerging. Worth piloting on a new Spectrum-X deployment.
- TELB: out of scope today. Revisit when UEC NICs ship in volume.
💡 What you should remember
| 🪜 | Four LB tiers, each adds one input | SLB (headers) → DLB (local link) → GLB (remote switch) → TELB (flow characteristics). |
| 🎰 | ECMP is SLB — a hash, not a load balancer | Same flow always picks the same path. Designed for diverse traffic, not synchronized elephants. |
| 🐘 | RoCE v2 cripples SLB entropy | Four of five hash fields collapse. The whole decision lives on UDP source port. |
| 🧵 | NCCL_IB_QPS_PER_CONNECTION=4 is free entropy | Set on every cluster. 4× the SLB headroom. Costs nothing. |
| 🧠 | DLB (flowlet adaptive routing) is today's default | ASIC tracks queue depth, reassigns at flowlet boundaries. ~1 ms reaction. Spectrum-3+, Tomahawk-4+, Silicon One G200+. |
| 🛰️ | TELB is shipping at hyperscale, not (yet) for you | MRC at OpenAI / Microsoft. SRD at AWS. UEC due 2025–26. Plan for it; don't deploy it. |
| 🚦 | LB ≠ failure detection | BFD / BGP / IP FRR react to dead paths, they don't spread load. Different problem class. |
Next: Load Balancing Playground → — pick a method, toggle between web and AI traffic, fail a spine, and watch it react live.