From CPU to GPU — what your fabric inherited
You've spent 20 years tuning networks around CPUs — small flows, decorrelated, TCP retransmits handle the occasional drop. AI runs on GPUs, and the network around them had to change because of it. This page is the why, and what it did to your wire.
- Explain why CPUs can't do AI — the four walls (compute, memory, model fit, parallelism) — and the network angle hidden in each.
- Contrast web traffic vs AI backend traffic — different per-flow size, different sync, different blast radius. Same wires.
- Recite the rule — a collective finishes when the slowest GPU finishes. Tail latency dominates everything else.
📖 GlossaryCPU / GPU / fabric terms — covers both pages of this chapterclick to collapse · keep open while you read
| Term | What It Means | Networking Analogy | |
|---|---|---|---|
| 🧮 | SM (Streaming Multiprocessor) | The execution unit on a GPU. H100 has 132 SMs × 128 CUDA cores each | A line card on a chassis switch — many in parallel |
| ⚡ | HBM (High-Bandwidth Memory) | RAM soldered directly to the GPU die. HBM3e ≈ 3 TB/s | TCAM glued to the silicon, ×30 the bandwidth |
| 🔗 | NVLink | NVIDIA's GPU-to-GPU interconnect. 900 GB/s per GPU on H100, 1.8 TB/s on B100 | The scale-up fabric — inside-the-box, TB/s |
| 🔗 | Infinity Fabric (xGMI) | AMD's GPU-to-GPU interconnect. ~896 GB/s–1.2 TB/s per MI300X | The AMD scale-up fabric — same role as NVLink |
| 🌀 | NVSwitch | The switch silicon that wires NVLink into an all-to-all mesh | A non-blocking crossbar at the chip level |
| 🚌 | PCIe Gen5 ×16 | CPU ↔ GPU ↔ NIC bus inside a server. ~128 GB/s | The backplane between blades |
| 📋 | SXM5 | The H100 form factor — module that plugs into a baseboard | A blade form factor, not a card |
| 🏠 | HGX / MGX / OAM | Baseboard / chassis standards that hold 4–8 GPUs | A reference chassis spec |
| 🌊 | Collective | A group communication primitive — AllReduce, AllGather, ReduceScatter, AllToAll | The AI version of LSA flooding |
| 🎯 | Tail latency | The p99 / p99.9 / p99.99 latency — where the slowest 1-in-10,000 packet lands | The outlier — in AI, it dominates everything |
| 📉 | Hash polarization | When ECMP collapses a small set of elephant flows onto the same path | Once it polarizes, it stays stuck |
| 🚧 | Oversubscription | Less uplink bandwidth than downlink. Standard 4:1 in DC, intolerable in AI | The cost-saver that died with AllReduce |
| 🚏 | Rail-optimized | 1 NIC per GPU, each pair on the same NUMA node | Strict 1:1 mapping between compute and uplink |
| 🧠 | Branch prediction | CPU trick: speculate which way an if-statement goes | GPUs don't bother — they run all paths in parallel |
1. Why GPUs, not CPUs
A CPU isn't slow at AI. A CPU is the wrong tool entirely. Four walls hit at once:
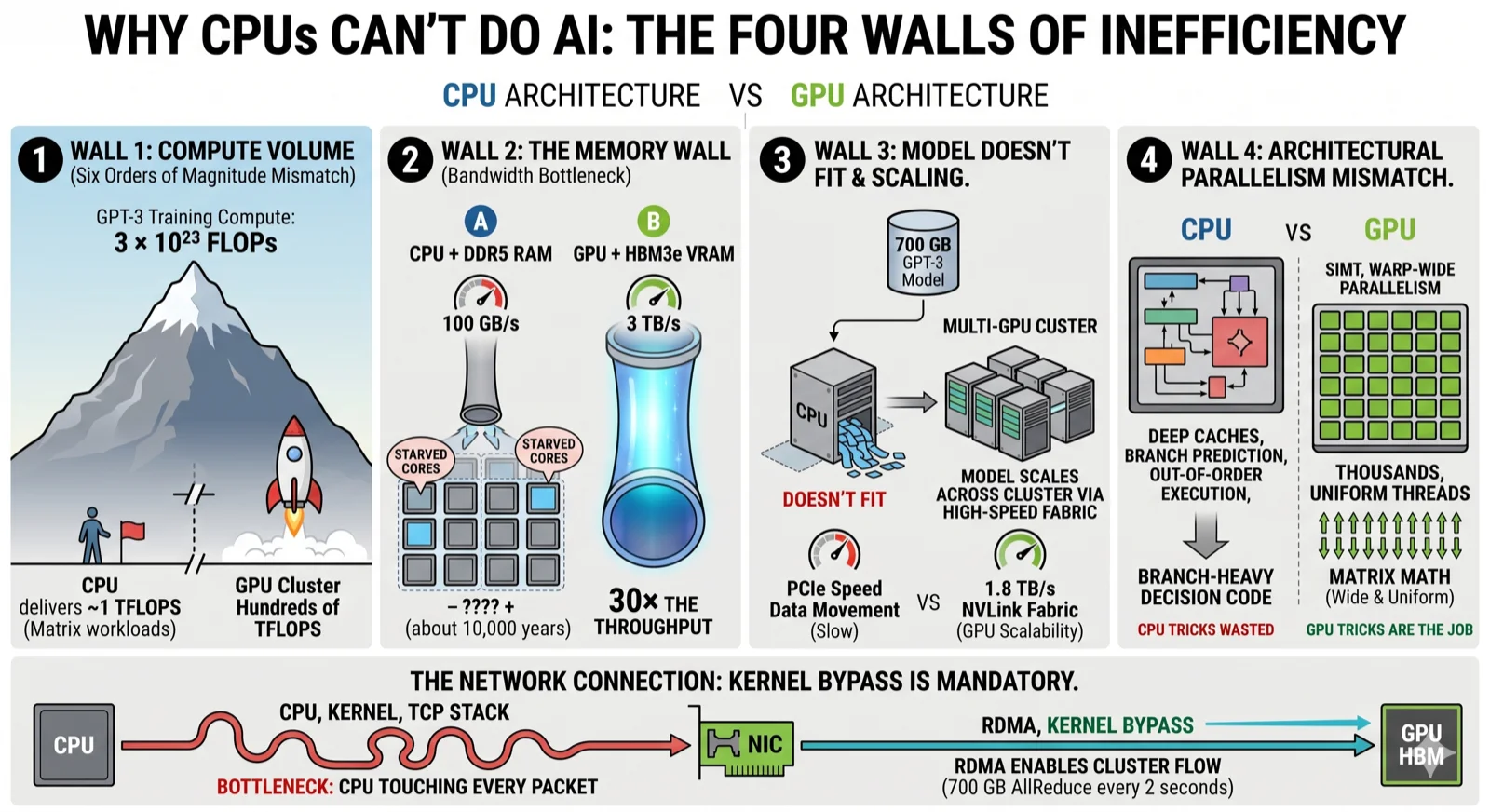
In one frame:
- Wall 1 — Math volume. GPT-3 training ≈ 3 × 10²³ FLOPs. A CPU delivers ~1 TFLOPS on matrix workloads. Single-CPU time: ~10,000 years. GPU cluster: weeks. Six orders of magnitude gap.
- Wall 2 — Memory bandwidth. DDR5 ~100 GB/s vs HBM3e ~3 TB/s. 30× the throughput. Even with 1,000× the cores, a CPU's RAM bus would starve them.
- Wall 3 — Model doesn't fit. GPT-3 = 700 GB. Spreading it across CPUs means moving most of it over the network every step — and CPUs at PCIe speed can't move 700 GB in 2 seconds. A GPU cluster moves it over a scale-up fabric instead — NVIDIA NVLink at 1.8 TB/s, or AMD Infinity Fabric (xGMI) at ~896 GB/s–1.2 TB/s per MI300X — both reading another GPU's HBM at memory-bus speeds.
- Wall 4 — Parallelism mismatch. CPUs are built for branchy, decision-heavy code. AI training is wide, uniform, branchless matrix math. Every CPU trick is wasted; every GPU trick (SIMT, warp-wide parallelism, HBM) is exactly the job.
And here's the network angle (the bottom band of the diagram): even if you scaled CPU cores for the math, the CPU couldn't keep up with the data movement. A 700 GB AllReduce hits the NIC every 2 seconds; a CPU touching every packet through the kernel is the bottleneck before the math is. RDMA exists because CPUs couldn't even handle the packet path. Kernel bypass isn't a nice-to-have — it's the only way the cluster runs at all.
2. What changed on your wire
Same wires. Two completely different problems:
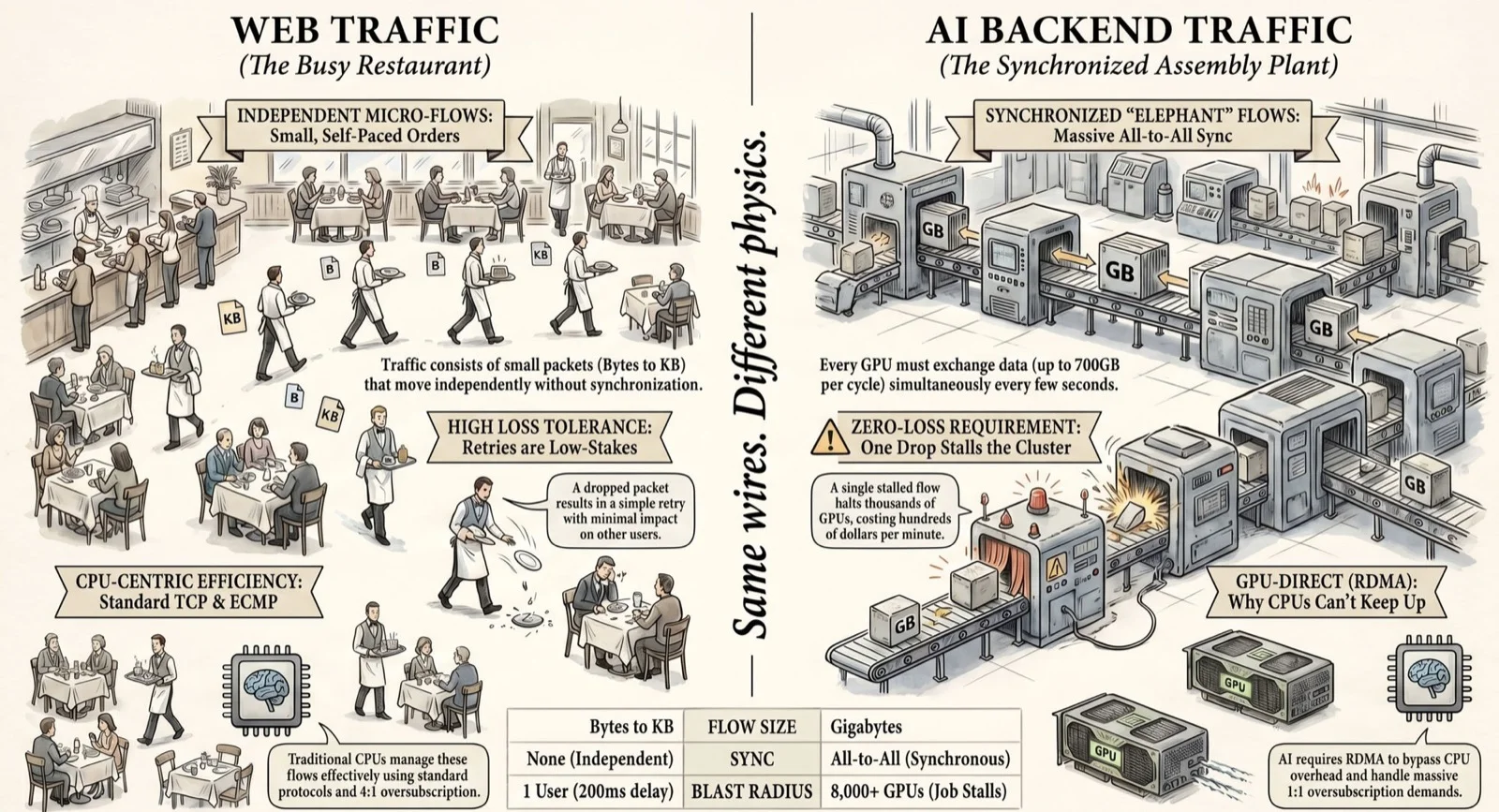
- Web traffic = a busy restaurant. Hundreds of customers, each ordering something different, each at their own pace. Independent. Drops are recoverable. The data plane you've spent 20 years tuning.
- AI backend traffic = an assembly plant. 8,000 workers building ONE car together. Every 2 seconds a bell rings, every worker syncs at the central yard, runs back, works 2 seconds, bell rings again. For weeks. One slow worker stalls all 7,999. Your new data plane.
The seven things that flip:
| Web (restaurant) | AI backend (assembly plant) | |
|---|---|---|
| Per-flow size | Bytes to KB | Gigabytes to terabytes |
| Sync between flows | None | All flows must finish at the same instant |
| Loss tolerance | Drop = retry, nobody notices | Drop = whole job stalls |
| ECMP behavior | Statistically balanced | Polarizes onto a few elephant flows |
| Oversubscription | 4:1 normal | 1:1 mandatory |
| Buffer absorption | Soaks up bursts | Fills in microseconds — PFC fires |
| Failure blast radius | One user, ~200 ms | All 8,000 GPUs, $/sec burning |
The bell ringing every 2 seconds is your AllReduce. Every GPU sends its gradient to every other GPU. No skipping. No buffering for later. The gradient is the same size as the model:
| Model | Gradient per step |
|---|---|
| Llama 2 7B | 28 GB |
| GPT-3 175B | 700 GB |
| Llama 3 405B | 1.6 TB |
For GPT-3, that's 700 GB synchronized across every GPU, every 2–5 seconds, for weeks. A collective finishes when the slowest GPU finishes — one slow link stalls thousands.
This is the inversion that broke 30 years of fabric design intuition:
You used to optimize for average throughput. Now you optimize for worst-case latency.
The p99.99 packet is the one you have to engineer for. (Full treatment of the traffic shape in What AI Does to Your Network.)
💡 What you should remember
| 🚫 | CPUs can't do AI | Four walls: ⛰️ math volume, 🚧 memory bandwidth, 📦 model doesn't fit, 🧠 wrong parallelism shape. |
| 🔗 | The traffic shifted | Web = many small independent flows. AI = a few synchronized elephant flows that finish together. |
| 🎯 | Tail latency is THE latency | A collective finishes when the slowest GPU finishes — one slow link stalls thousands. |
| 💥 | 0.1% loss = 10× throughput hit | RDMA has no graceful retransmit. Loss is catastrophic, not "fine." |
| 🚧 | Oversubscription died | 4:1 was normal in your DC. AI fabrics are 1:1. No exceptions. |
Next: Inside GPU Anatomy → — open the box. The GPU vendor landscape, NVLink, NVSwitch, RDMA NICs, and a component-by-component walk of the DGX H100 reference design.