What AI Does to Your Network
You don't need calculus. You don't need to read a research paper. You need to know what AI training does to your network.
Here it is — in one table, four phases, and one inversion that defines the whole fabric.
- Translate "we trained a 7B model" into traffic — how big the gradient is, how often it syncs, what that means at line rate on your fabric.
- Map every AI term you'll meet (gradient, AllReduce, optimizer, batch, step) to a networking analogue — so the next AI paper or NCCL log isn't opaque.
- Understand why one dropped packet is catastrophic — and why "lossless" isn't marketing here.
- Care. A 1,024-GPU stall costs $512/minute. Your PFC threshold has a dollar value now.
📖 GlossaryThe AI ↔ Network Engineer translatorclick to collapse · keep open while you read
| AI Term | What It Means | Networking Analogy | |
|---|---|---|---|
| 🔢 | Parameter / Weight | One number in the model | One entry in a routing table |
| 📡 | Gradient | How much to adjust each parameter | OSPF cost update |
| 🎯 | Loss | How wrong the model is (lower = better) | Convergence metric |
| 📦 | Batch | Multiple training examples processed at once | Bulk route computation |
| 🔄 | Epoch | One complete pass through the entire dataset | Full topology sweep |
| 👣 | Step | One forward + backward + update cycle | One SPF calculation |
| 🎚️ | Learning rate | How big each adjustment is | OSPF cost multiplier |
| ⚙️ | Optimizer | The algorithm that applies gradients | SPF, but for matrices |
| 🌐 | AllReduce | Every GPU shares its gradient with every other | LSA flood |
| 📚 | NCCL | NVIDIA's library that orchestrates collectives | Routing daemon for AI |
1. Wait — what is "AI", exactly?
A model that learned to predict the next token, the next pixel, or the next action.
When ChatGPT answers a question, it's predicting one word at a time. When Stable Diffusion generates an image, it's predicting one pixel cluster at a time. When a self-driving stack brakes for a kid, it's predicting "the right action."
Behind every one of these is the same thing: a giant set of numbers (the model) that was trained on a lot of data. Training is what creates the model. Inference is what happens when you use it.
2. AI is an east-west traffic problem
Most network engineers think of AI as "ChatGPT" or "GPUs somewhere." From your seat, it's not. AI is a massive east-west traffic problem.
For twenty years, you designed networks where the traffic flowed north-south — user requests in, responses out. Bursty. Small packets. Independent backend servers. Millisecond latency was fine. A dropped packet here or there was fine.
AI broke every one of those assumptions:
| Traditional DC | AI training DC | |
|---|---|---|
| Traffic direction | North-south (user ↔ app) | East-west (GPU ↔ GPU) |
| Packet pattern | Bursty, small, independent | Synchronized, large, every 2–5 s |
| Servers | Loosely coupled | One cluster acts as one computer |
| Latency tolerance | Milliseconds | Microseconds |
| Loss tolerance | Some loss = bad UX | Some loss = whole cluster stalls |
| Network's role | Connect things | Be part of the compute system |
AI is a networking problem disguised as a compute problem. The compute people built thousands of GPUs that act like one machine. Whether those GPUs actually act like one machine is up to your fabric.
3. Training vs inference — the two lives of a model
Training is how the model gets built. Inference is how it gets used. Same model, two completely different network problems — one is bandwidth-bound and synchronous, the other is latency-bound and asynchronous.
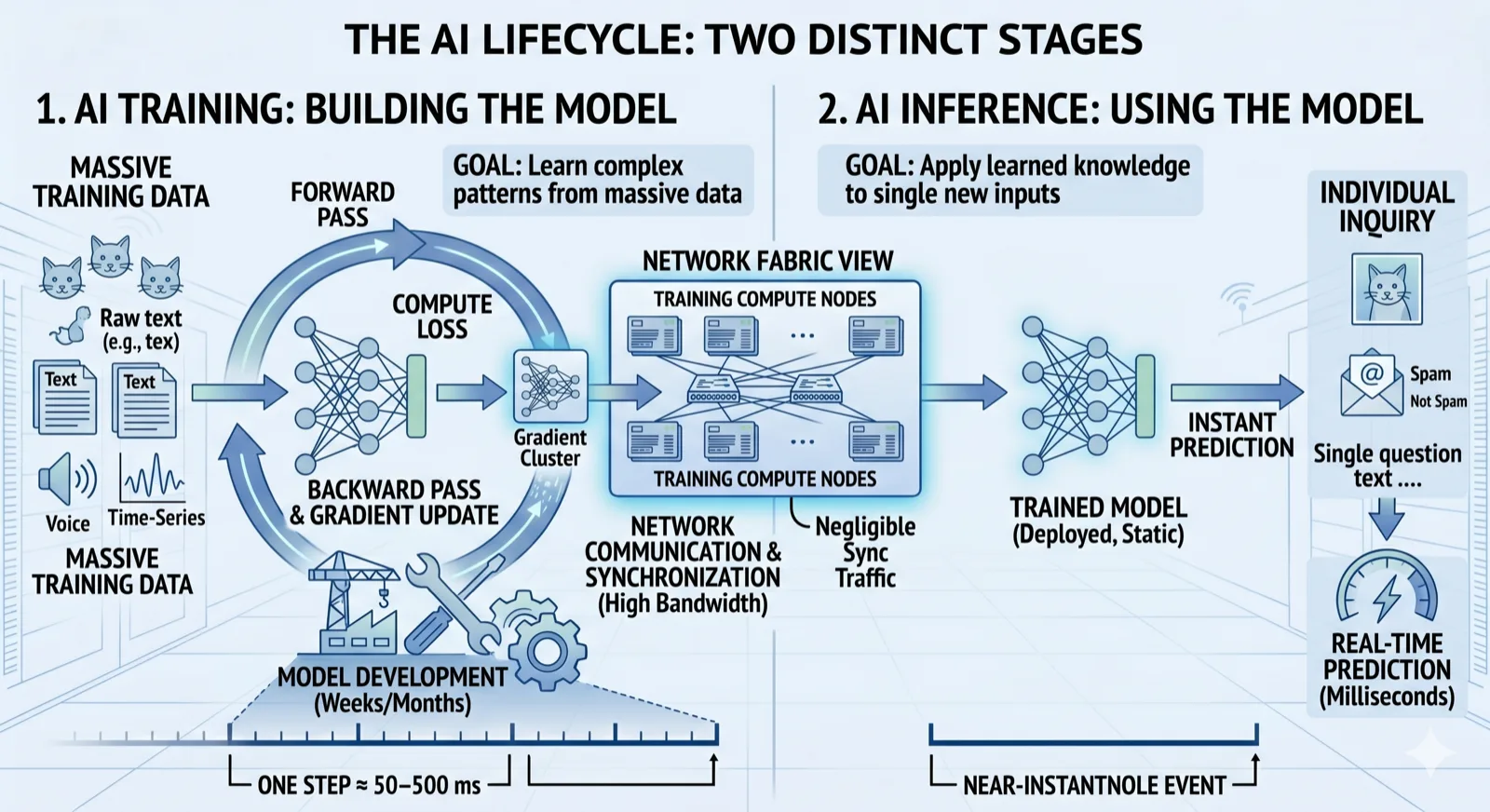
| Training | Inference | |
|---|---|---|
| When | Once, up front | Continuously, in production |
| Duration per workload | Weeks to months | Milliseconds per request |
| GPUs involved | 1,000 to 100,000+ | 1 to a handful |
| Network shape | Massive synchronous gradient sync every 2–5 s | Small async request / response |
| Bandwidth pressure | Brutal | Modest |
| Latency pressure | Modest (you wait weeks anyway) | Brutal (sub-second SLOs) |
| Why your fabric cares | Gradient sync is the fabric's daily job | Request routing is one concern among many |
This curriculum is mostly about training. It's where the network gets the most punishment. Inference fabrics are a different problem with their own design rules — covered in Phase 6.
4. Three flavors of training, same network shape
You'll hear AI engineers talk about three styles. The math differs. From your fabric's view, all three look identical.
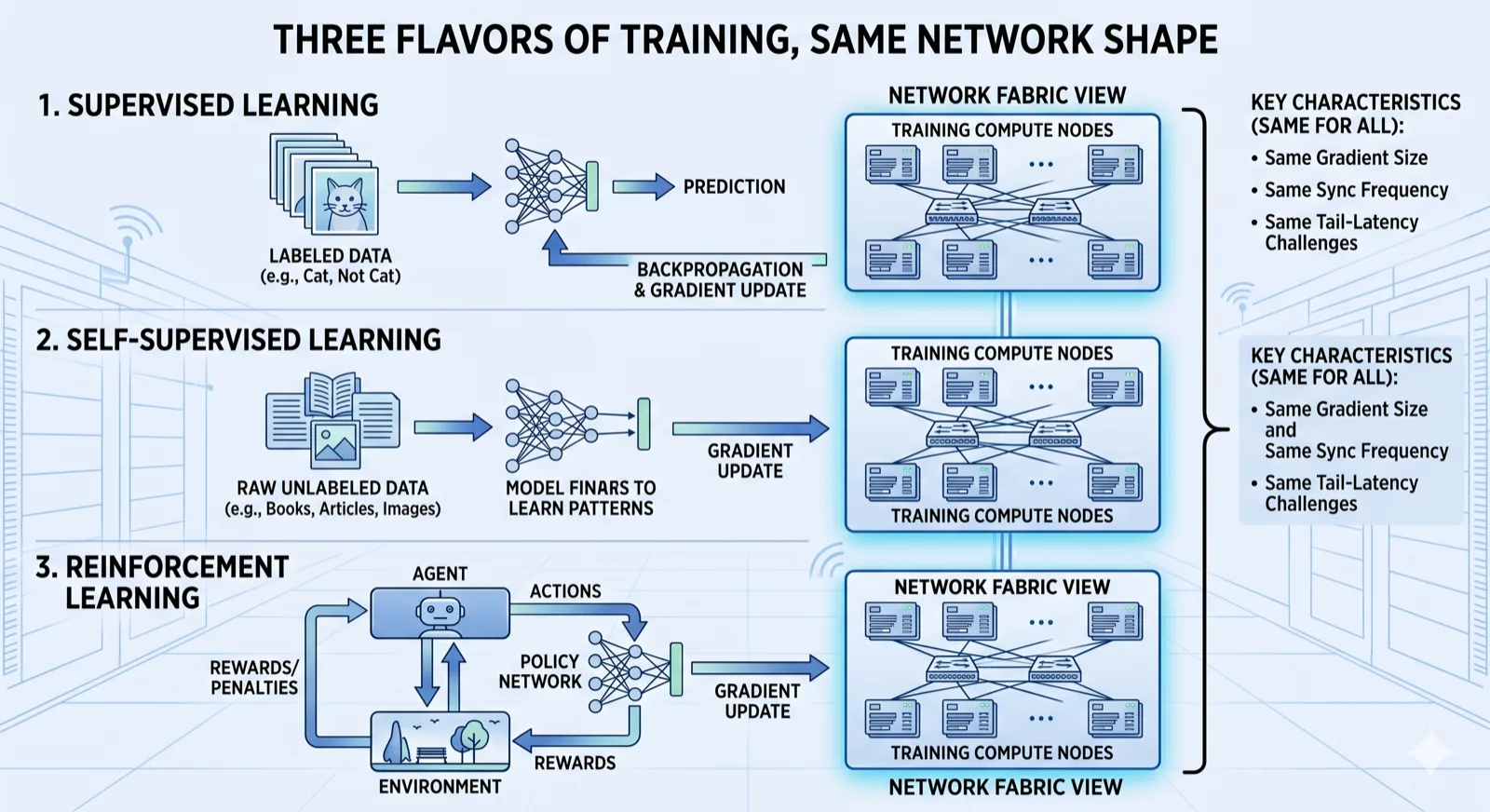
Same gradient size. Same sync frequency. Same tail-latency problem. Same fabric, same job. When this curriculum says "training," it means any of the three.
5. A model is a giant routing table
A neural network takes an input — text, image, audio — and produces an output. The thing that maps input to output is the parameters (also called weights). They're just numbers. Billions of them.
| Model | Parameters | Size in memory |
|---|---|---|
| ResNet-50 (image classifier) | 25 M | 100 MB |
| Llama 2 7B | 7 B | 28 GB |
| GPT-3 | 175 B | 700 GB |
| Llama 3 405B | 405 B | 1.6 TB |
| GPT-4 (est.) | 1.8 T | 7.2 TB |
These aren't file sizes. Every GPU in the cluster holds a full copy. A 1,024-GPU GPT-3 training job has 1,024 × 700 GB of identical weights spread across the cluster.
6. Training is a loop
If a model is a giant routing table, then training is OSPF convergence. You start with random routes (a garbage parameter set). You feed traffic through the network (training data through the model). You measure how badly it routes (compute the loss — how wrong the model is). Then you adjust the routes (update the parameters). Repeat millions of times. The routes get better. The loss goes down. The model converges.
The difference: OSPF converges in seconds. Frontier-model training converges in weeks, across thousands of GPUs, costing millions of dollars per run.
Every training step is the same four phases — and the whole thing cycles back to step 1, for hundreds of thousands of iterations:
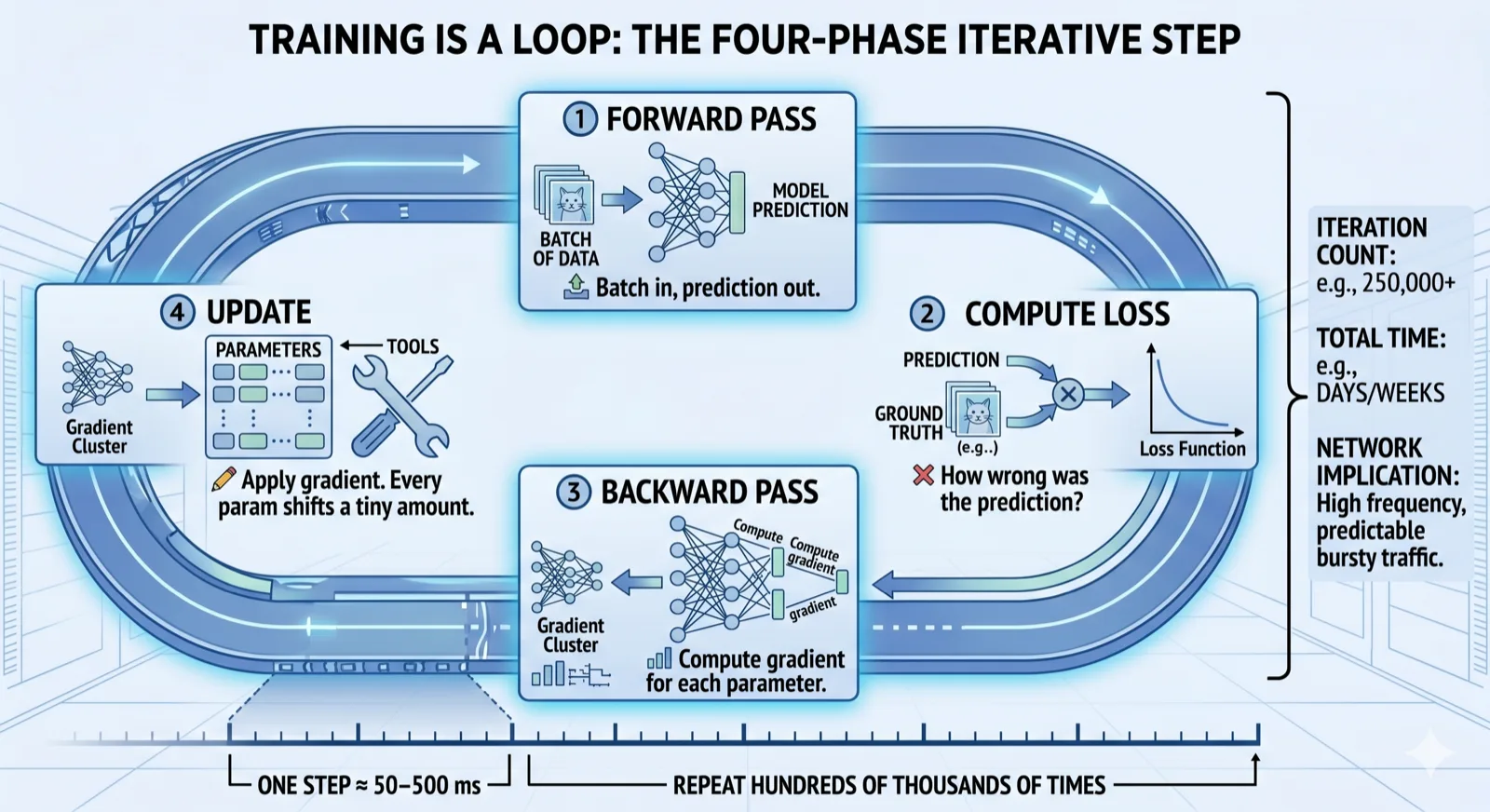
That's one step. Frontier models run for hundreds of thousands of steps. Weeks of wall-clock time. Every iteration of step ③ is what produces the gradient — and that gradient is what your fabric has to carry.
7. The number that defines your fabric
The gradient from step 3 is the same size as the model itself.
| GPT-3 model size | 700 GB |
| Gradient per step | 700 GB |
| Sync frequency | every 2–5 seconds, sustained |
| What every GPU has to share with every other | 700 GB |
| 400 Gbps NIC capacity | 50 GB/s |
| Time to move 700 GB on one 400G NIC | 14 seconds |
| Time budget | 2 seconds |
There's the inversion. You need to move 700 GB in 2 seconds; one NIC takes 14. That's why GPU servers have 8 NICs — not for redundancy, for parallel aggregation. That's why every NIC is 400 Gbps moving to 800. The network is the bottleneck.
8. Lab 1 — see a training loop on a tiny model
Before going further, watch the same loop run on a small model. Same shape as a 175 B run — only the constants change. The loss curve drops, accuracy climbs from ~10% to ~98% in front of you:
That's training on one GPU. The same loop runs with 1,000 GPUs — but every step now ends with a sync step where every GPU shares its gradient with every other. That's where your fabric enters the picture. That's what the rest of this page is about.
9. How the GPUs stay in sync
Every GPU produces its own gradient. Before step N+1 can start, every GPU needs the averaged gradient across all GPUs. There's no shortcut. There's no GPU 0 acting as "the server" — that would be a bottleneck.
Imagine 8,000 musicians in an orchestra playing one piece. Every second they all stop, exchange notes with every other musician, and continue. If one musician's signal arrives 200 ms late, all 7,999 wait. The whole orchestra runs at the speed of the slowest exchange.
That synchronization is what AI engineers call AllReduce. In networking terms, it's an OSPF flood — every router needs every other router's update before convergence — except it happens every two seconds, sustained, for weeks.
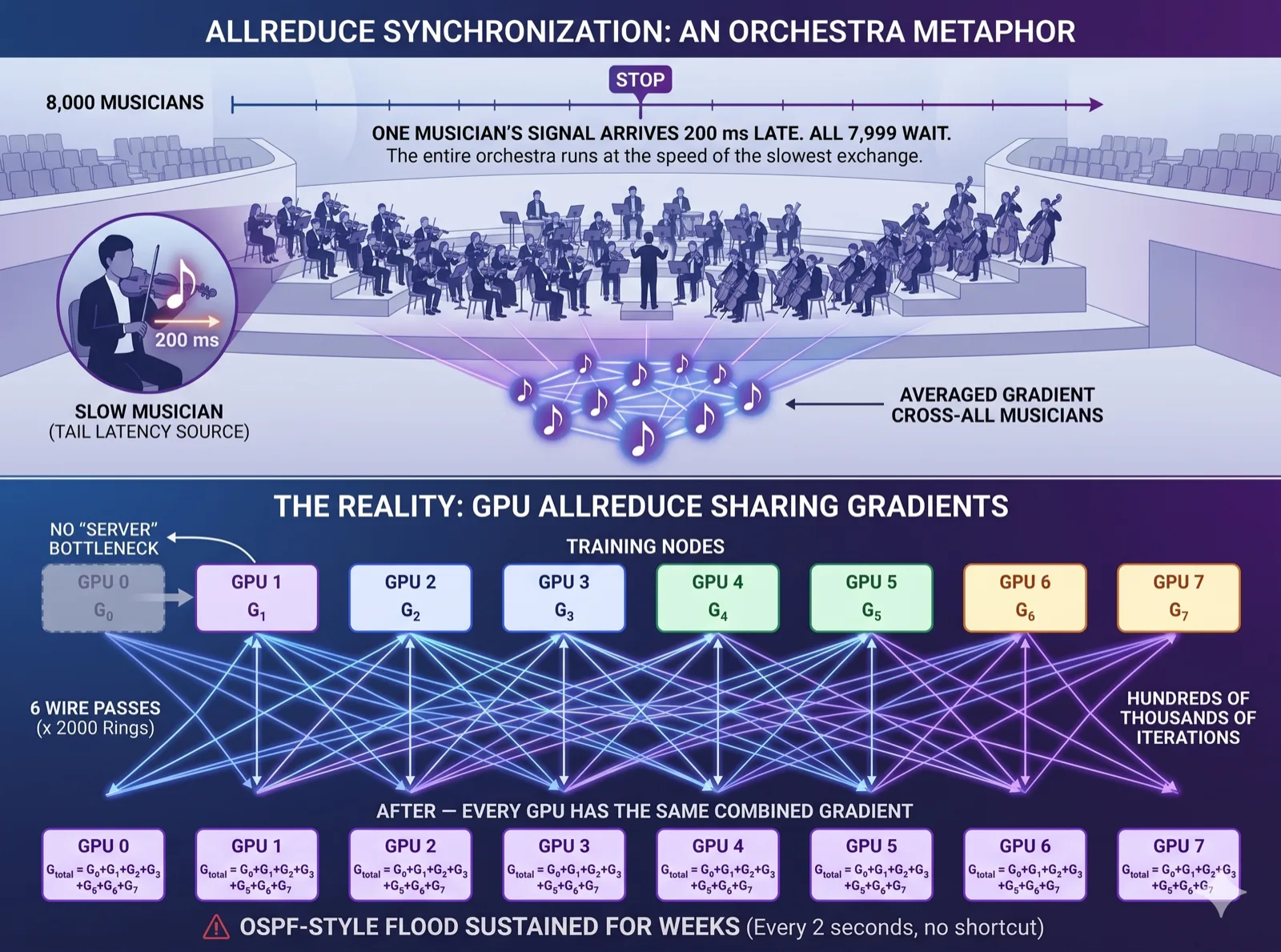
For now, the take-away: elephant flows between every pair of GPUs, simultaneously, every 2–5 seconds, for the duration of the training run. The mechanics — ring algorithms, bandwidth-optimal math, the 380 GB/s baseline you should measure on nccl-tests — live in Communication Libraries (Phase 3, section 09).
10. One dropped packet stalls the cluster
In a web app, a dropped packet costs one user 200 ms and nobody notices.
In AI training, a dropped packet stalls everyone. The trace:
- GPU-7 on
host-342sends a gradient fragment to GPU-3 onhost-891. - One packet drops.
- RDMA doesn't quietly retransmit like TCP. It go-back-N's millions of bytes — or fails the whole transfer.
- GPU-3 can't complete its part of AllReduce.
- No GPU can start step N+1 until AllReduce finishes.
- All 8,000 GPUs sit idle, burning electricity, waiting.
This is why an AI fabric has to be lossless — not "low loss," not "five nines." Zero drops on the RDMA priority class. PFC, ECN, and DCQCN are the three knobs that get you there. Phase 4 of this curriculum is the whole story.
Lab 2 — feel what one dropped packet costs
Same small training job, run four times — clean, +latency, +loss, both. Watch what each does to training time:
| Run | Network condition | Result |
|---|---|---|
| 1 | Clean | ~11 s baseline |
| 2 | +100 ms latency | ~27 s (2.5× slower) |
| 3 | +10% packet loss | ~60 s (5–6× slower) |
| 4 | +50 ms latency + 1% loss | hangs |
This is TCP doing its best to retransmit. In production NCCL uses RDMA — no quiet retransmit, drops are even more catastrophic.
11. The cost of waiting
| Cluster size | Cost / hour | Cost / minute | Cost / second idle |
|---|---|---|---|
| 256 H100s | $7,680 | $128 | $2.13 |
| 1,024 H100s | $30,720 | $512 | $8.53 |
| 4,096 H100s | $122,880 | $2,048 | $34.13 |
At ~$30/hour per H100, a 1,024-GPU job burns $512 every minute the network stalls it. A 10-second stall costs $85. A congestion event degrading training 10% for an hour wastes $3,000.
Your PFC threshold has a dollar value. Your ECMP hash distribution has a dollar value. Engineering decisions you used to make on intuition are now financial decisions.
12. Where the GPUs land changes everything
Same job — "I need 8 GPUs" — can hit your fabric or skip it entirely, depending on where the scheduler places them:
| Where the GPUs are | Path | Hits your fabric? |
|---|---|---|
| 8 on same server | NVLink (1.8 TB/s in-server) | ✅ No — invisible to you |
| 4 + 4, same ToR | server → ToR → server | 🟡 Yes — one hop |
| 4 + 4, different ToRs | server → leaf → spine → leaf → server | 🔥 YES — spine crossing, every step |
Scheduler placement is a network design decision now. Rail-optimized topology — covered in Phase 2 — exists because of this.
Imagine 8,000 construction workers building a house together. Every 3 seconds, every single worker has to stop, share their progress with every other worker, wait for everyone to sync up, then continue. If one worker's walkie-talkie drops a message, all 7,999 stand idle until it's resent.
At $128/minute for a 256-GPU cluster — or $2,048/minute for a 4,096-GPU job — your network is the walkie-talkie system. A crackly signal costs real money.
💡 What you should remember
| 🧠 | Model | A giant set of numbers (parameters), adjusted across millions of training steps to make the model less wrong. 🎯 Every GPU in the cluster holds a full copy. |
| 📡 | Gradient | Your network traffic — same size as the model, ⏱️ synced every 2–5 s, 📆 sustained for weeks. |
| 🔄 | AllReduce | How gradients get shared. ⏸️ Until it finishes, no GPU starts the next step. |
| 🚫 | Zero drops | RDMA has no graceful retransmit. 💥 One dropped packet stalls the whole cluster. |
| 💵 | The bill | A 1,024-GPU stall costs 💸 $512 a minute. Your PFC threshold has a dollar value. |
Next: GPU & Server Hardware → — the machine on the other end of every AllReduce. GPUs, NVLink, NVSwitch, RDMA NICs, PCIe — the box you've been talking about. Diagnostic depth (MFU, the 60-second triage card) lives in Production Operations once you've finished the curriculum.