Design Options — the landscape
Now you understand why the fabric is different. Next question: what shape do you build?
The industry has converged on four patterns. Each one optimizes a different axis — cost, scale, predictability, or operational simplicity — and each one has a sweet spot in cluster size. This page is the map: what each pattern is, when each one wins, and how to pick. The deep dives sit in the next two pages.
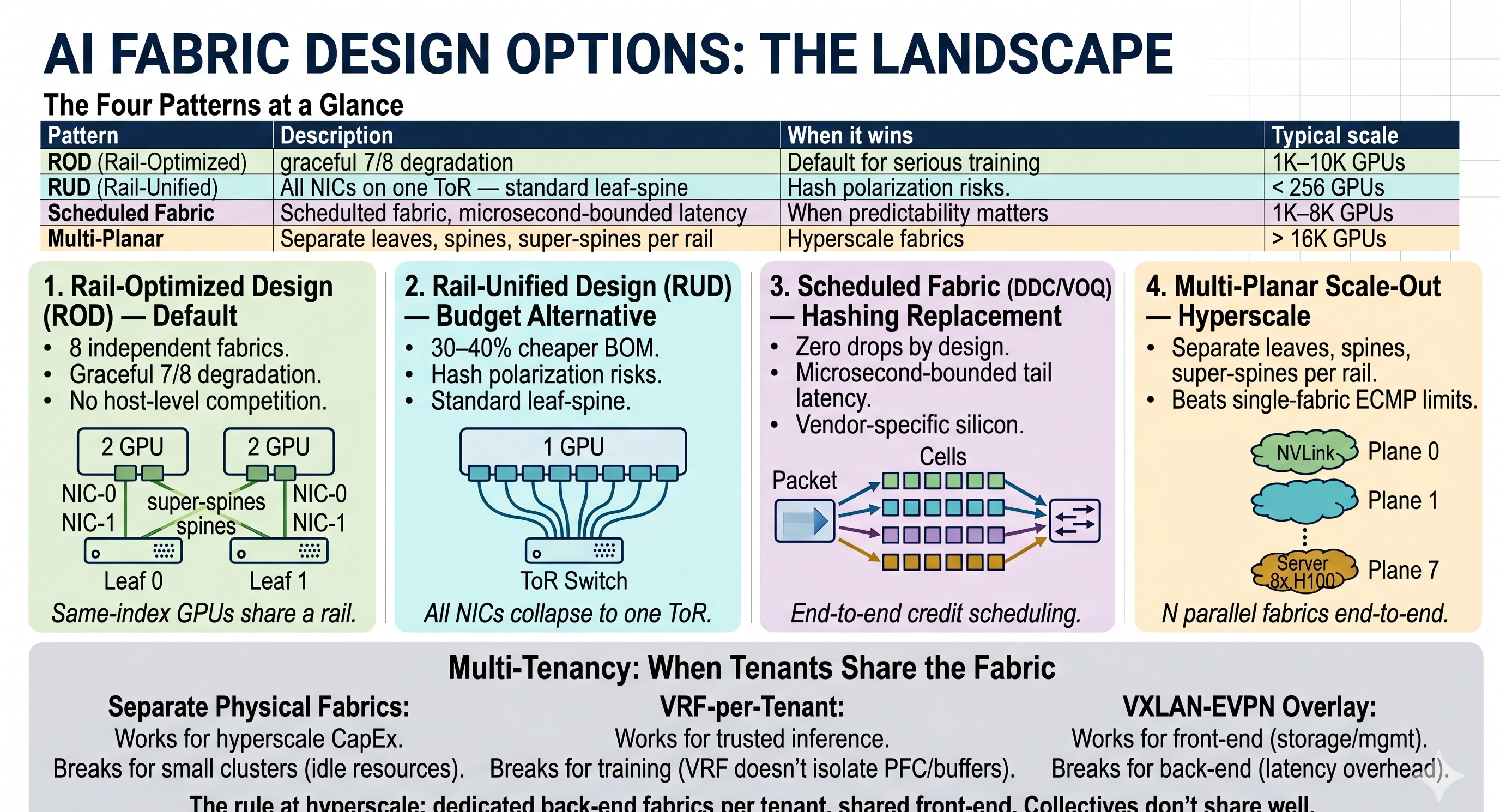
The whole landscape on one card. The four sections below walk each pattern in depth.
- Name the four fabric patterns and their sweet spots — ROD (1K–10K GPUs), RUD (< 256), Scheduled Fabric / DDC-VOQ (1K–8K), Multi-Planar (> 16K).
- Justify ROD as the default — eight rails, same-index GPUs share a rail leaf, ECMP polarization drops, and graceful 7/8 degradation on a leaf failure.
- Trade RUD vs Scheduled Fabric — RUD's 30–40% cheaper BOM that falls apart above ~512 GPUs, versus credit-based zero-drop forwarding at 1–5 µs/hop locked to Broadcom Jericho3-AI / Cisco Silicon One.
- Make the multi-tenancy call — separate physical fabrics vs VRF-per-tenant vs VXLAN-EVPN, and why you never co-mingle back-end RoCE with front-end storage/management.
1. The four patterns at a glance
| Pattern | One-line description | When it wins | Typical scale |
|---|---|---|---|
| Rail-Optimized Design (ROD) | Each GPU NIC lands on its own dedicated rail leaf; same-index GPUs share a rail. | Default for serious training clusters. | 1K–10K GPUs |
| Rail-Unified Design (RUD) | All NICs on one ToR per host — classic leaf-spine, just non-blocking. | Cost-sensitive, small clusters, or inference. | < 256 GPUs |
| Scheduled Fabric (DDC / VOQ) | Cell-based forwarding with end-to-end credit scheduling — no hashing, no drops. | Predictability matters more than vendor freedom. | 1K–8K GPUs |
| Multi-Planar Scale-Out | N parallel fabrics, each owning one rail end-to-end. | Hyperscale where single-fabric ECMP polarization breaks down. | > 16K GPUs |
2. ROD — the default
Each GPU NIC lands on its own dedicated rail leaf. NIC-0 across every host shares Rail Leaf 0, NIC-7 shares Rail Leaf 7 — eight rails, eight independent fabrics. Same-index collectives never compete with other GPUs on the host, ECMP polarization drops sharply, and you get graceful 7/8 bandwidth degradation on a leaf failure. This is the default you'll see at 1K–10K GPUs across NVIDIA reference designs, Meta, and most enterprise builds.
Deep dive on the next page: 3.3 Rail-Optimized Design (ROD) →.
3. RUD — the budget alternative
All NICs on one ToR per host. It's the classic leaf-spine you already know, just non-blocking. The fabric BOM is 30–40% cheaper because you collapse 8 rail leaves into 1 ToR and cut cabling 8×. The cost: every cross-server collective crosses the spine, which means hash polarization and elephant-flow pain show up early. RUD wins below ~256 GPUs; it loses above ~512 when collective traffic starts saturating spine uplinks.
4. Scheduled Fabric — replace hashing with credits
Instead of hashing flows across links and praying, the destination switch grants credits before traffic flows. Packets get sliced into fixed-size cells, sprayed across all paths, reassembled at the egress. Result: no hash polarization, zero drops by design, and microsecond-bounded tail latency. The cost is ~1–5 µs per hop of scheduling overhead and a vendor-specific silicon dependency (Broadcom Jericho3-AI, Cisco Silicon One G200). Wins when predictability matters more than vendor freedom.
5. Multi-Planar — for hyperscale
N parallel fabrics, each owning one rail end-to-end — separate leaves, separate spines, separate super-spines. Used past ~16K GPUs when single-fabric ECMP polarization becomes unmanageable no matter how good your adaptive routing is. NVIDIA DGX SuperPOD (8 planes), Meta GenAI clusters, and Google TPU pods (via optical circuit switches) all use multi-planar variants. The trade-off is N× switches, N× cabling, N× management surface — only worth it when the alternative is throughput loss to polarization.
6. Multi-tenancy — when tenants share the fabric
This question comes up early and the honest answer is uncomfortable: the back-end RoCE fabric is almost never multi-tenant in practice. The latency budget kills it. When operators do share, three patterns show up:
| Pattern | Works when | Breaks when |
|---|---|---|
| Separate physical fabrics per tenant | Hyperscale, big tenants, you can afford the CapEx. | Smaller clusters where the per-tenant fabric sits idle most of the day. |
| VRF-per-tenant on a shared fabric | Small clusters, trusted tenants, mostly inference. | Training collectives — VRF doesn't isolate PFC or shared buffer pressure across tenants. |
| VXLAN-EVPN overlay | Standard on front-end (storage, mgmt, ingress). | Almost never on the back-end — encap adds latency and most NICs don't offload it cleanly for RoCE. |
The pattern at hyperscale is dedicated back-end fabrics per tenant, shared front-end via VXLAN-EVPN. Don't try to be clever here — collectives don't share well.
7. Pick your design
The decision is mostly driven by cluster size, then workload mix (training vs inference), then vendor preference and budget. Here's the short version you can use right now:
- < 256 GPUs? → RUD. Cheap, simple, fast enough.
- 256–1K GPUs? → ROD. Worth the cabling complexity at this scale.
- 1K–10K GPUs? → ROD + adaptive routing (or packet spraying). ECMP alone won't cut it.
- > 16K GPUs? → Multi-planar. Single-fabric polarization stops being fixable.
- Cost-sensitive at 1K–4K AND you're OK with Broadcom-only? → Scheduled fabric. Predictability for the price of vendor lock-in.
Co-mingling the back-end (RoCE) and front-end (storage + management) on the same switches. It looks like you're saving ports and CapEx — until the first training job runs and storage traffic shares buffers with collective traffic, PFC pauses propagate across both planes, and a benign storage hiccup stalls a 1K-GPU job. Two separate physical fabrics, always.
💡 What you should remember
| 🗺️ | Four patterns, one decision | ROD, RUD, Scheduled, Multi-Planar. The choice is driven by cluster size first, then workload and budget. |
| 🎯 | ROD is the default | At 1K–10K GPUs with serious training, rail-optimized wins almost every time. Everything else is a deviation with a reason. |
| 💰 | RUD is the budget escape hatch | 30–40% cheaper fabric BOM, works below ~256 GPUs, falls apart above ~512. |
| 🎟️ | Scheduled fabric trades flexibility for predictability | Credit-based, zero-drop, 1–5 µs scheduling overhead, locked to Broadcom/Cisco silicon. |
| 🛤️ | Multi-planar is for past 16K GPUs | When polarization stops being fixable, build N parallel fabrics. N× everything. |
| 🚫 | Back-end RoCE is not multi-tenant | Separate physical fabrics per tenant at hyperscale, VRF for small/trusted clusters, EVPN overlay only on the front-end. |
| ⛔ | Never collapse back-end and front-end | One fabric for collectives, one for everything else. Always. |
Next: Rail-Optimized Design (ROD) → — the deep dive on the default pattern: what wires to what, why blast radius gets better and worse at the same time, and how to size a pod.