Cluster Sizing & Cabling
You've picked the design (3.2) and the deep-dive (3.3 — ROD). Now: how many leaves? How many spines? How much fiber? This page is the BOM math and the day-1 install reality. Vendor stacks — Spectrum-X, Tomahawk, Jericho3-AI, Silicon One, Arista — live on the blog.
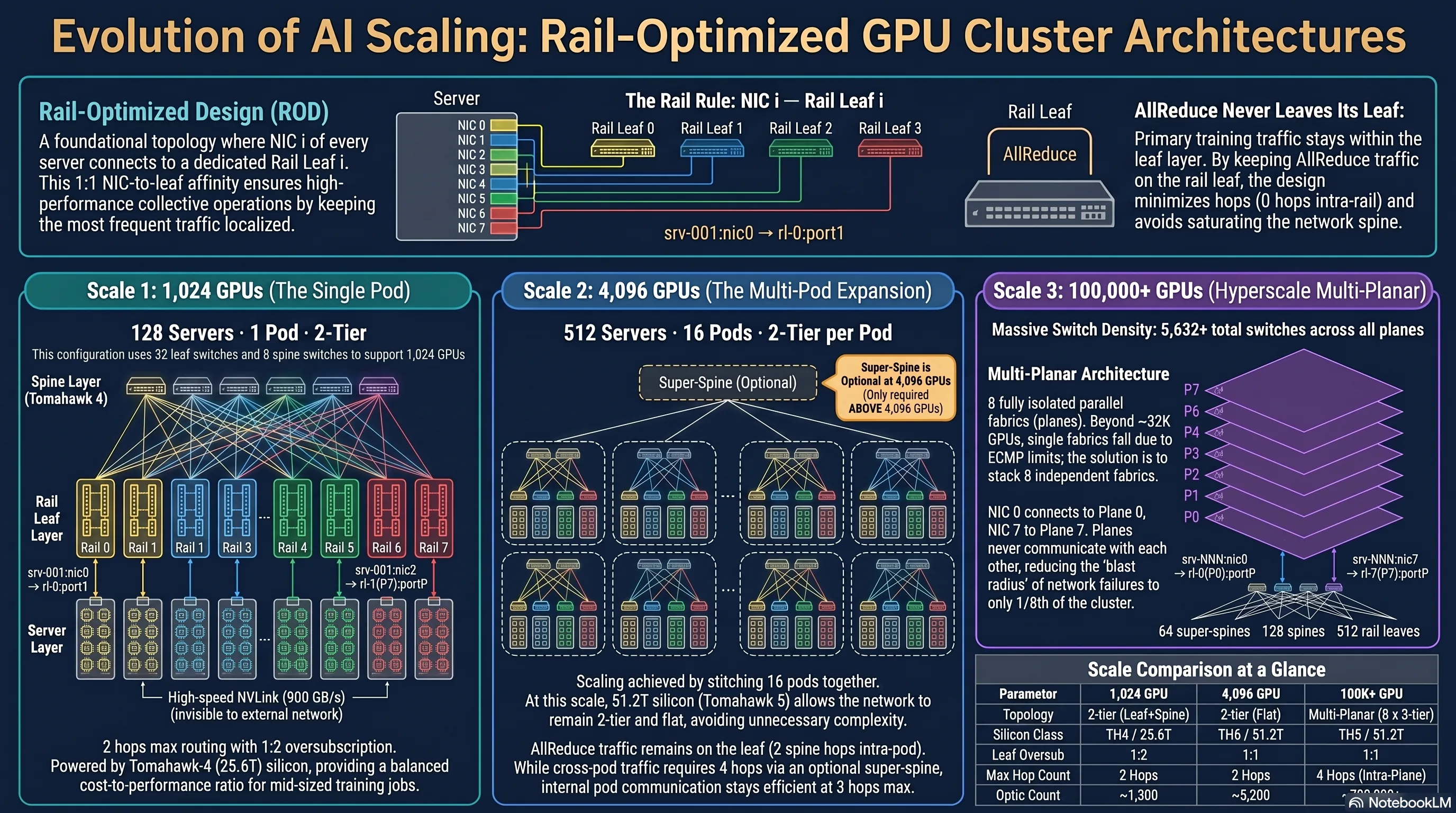
- Size a pod from leaf radix — apply R/2 servers per rail at 1:1 so
R=64→ 32 servers × 8 rails = 256 servers / 2048 GPUs, and read leaf oversub (1:2 at R=32 down/16 up). - Lay out reference fabrics at scale — 1024 (2-tier, 8 spines), 4096 (2-tier on 51.2T silicon — no super-spine — or 3-tier from smaller pods), 16K (3-tier, near the ECMP limit), 100K+ (8 planes).
- Pick the right transceiver by reach — DAC ≤ 3 m in-rack, AOC ≤ 30 m across rows, OSFP MMF ≤ 100 m, SMF km-class, and watch the OSFP vs QSFP-DD form-factor mismatch.
- Build a cabling scheme that survives day-1 —
<server-id>:<nic-index> → <rail-leaf-id>:<port>labels both ends, colour-code by rail, run a post-install cabling checker, and spare 10–20% optics.
1. Reference designs at each scale
The numbers below assume 400G per GPU NIC and 8 GPUs per server — the modern H100/H200/B200 baseline. Swap to 800G and the GPU counts double for the same switch radix.

1024 GPUs — single pod, 2-tier
128 servers × 8 GPUs. Eight rails of 4 leaves each = 32 leaves total. 8 spines. Each leaf: 32 × 400G down (servers) + 16 × 400G up (spine) = 1:2 oversub at the leaf. Some shops push for 1:1 here by going to R = 64 leaves — your call, your budget.
Spine fanout: each spine takes 4 uplinks from every leaf in its rail (4 leaves × 8 rails = 32 ports). One spine = 32 × 400G. Sized to a Tomahawk 4 (25.6 Tbps) or half a Tomahawk 5.
Worked example — 1024× NVIDIA Blackwell B300 at 800G
Same 1024 GPUs, current Blackwell generation — and the whole BOM shifts because the rails jump to 800G. Background: 128× HGX B300 servers, 8× B300 each (288 GB HBM3e per GPU). NVLink 5 + on-board NVSwitch keep the 8 GPUs all-to-all inside the box at 1.8 TB/s; one ConnectX-8 800G SuperNIC per GPU faces the fabric — 8× 800G = 6.4 Tb/s scale-out per server. The fabric only ever sees the 800G rails; NVLink never leaves the chassis.
Fabric switch = 64 × 800G (NVIDIA Spectrum-4 SN5600 or Broadcom Tomahawk 5). Non-blocking leaf = 32 down + 32 up.
| Component | Count | Detail |
|---|---|---|
| HGX B300 servers | 128 | 8× B300, 288 GB HBM3e per GPU |
| B300 GPUs | 1,024 | NVLink 5 scale-up, 1.8 TB/s per GPU |
| ConnectX-8 800G rail NICs | 1,024 | 1 per GPU → 8× 800G per server |
| Leaf (rail) switches | 32 | 4 per rail × 8 rails |
| Spine switches | 16 → 32 | 2 per rail (1:1 min) → 4 per rail (recommended) |
| Total fabric switches | 48–64 | SN5600 / Tomahawk-5 class, 64× 800G |
| Server→leaf cables | 1,024 | 800G; DAC in-rack, AOC across the row |
| Leaf→spine cables | 1,024 | 800G OSFP |
| Aggregate / bisection | 819 Tb/s / ~409 Tb/s | host-side / full bisection |
The leaf count is fixed: 128 servers at 32-per-leaf is 4 leaves per rail × 8 rails = 32 leaves. Spines are your ECMP-and-HA dial — 2 per rail is the bare 1:1 minimum (only 2-way ECMP), 4 per rail is the production default (4-way ECMP, and a lost spine just drops that rail to 3/4 bandwidth instead of taking it down).
This stays a single 2-tier pod — no super-spine. 1,024 sits well under the ~8,192-GPU ceiling a 2-tier fabric reaches at 51.2T, and the multiple spines give you the path redundancy a single 800G rail NIC can't (you can't dual-home one GPU port). IB variant: swap Spectrum-4 for Quantum-X800; ConnectX-8 and the radix math are unchanged.
4096 GPUs — 2-tier on big silicon, 3-tier from smaller pods
This is the scale where switch radix decides the tier count — and it's the most common point of confusion. Do you need a super-spine at 4096? Only if you're stitching together smaller pods.
- On 51.2T silicon (Tomahawk 5 = 128×400G, Spectrum-4 = 64×800G), 4096 is a single 2-tier pod. A 2-tier pod scales to ~8192 GPUs at this radix (the
R²/2math from §2), so 4096 fits comfortably with leaf + spine only — no super-spine, no third tier. Every flow is 2 hops. - Built from 1024-GPU pods (Tomahawk-4-class, 64×400G), 4096 is 4 pods and needs a 3-tier fabric. That third tier is the super-spine: 512 servers, 128 leaves, 32 spines, 16 super-spines. A pod-local job stays 2 hops (leaf → spine → leaf); cross-pod adds the super-spine hop — 4 hops worst case.
So the super-spine earns its place only once you pass a single pod's 2-tier ceiling (~8192 GPUs at 51.2T) — or when you deliberately build in pod units for blast-radius and scheduling isolation, even though the radix would let you go flat.
Either way, rail-affinity scheduling pays off: keep a job inside one pod (or one spine group) and you minimize the longest hop and the cross-pod tail latency.
16384 GPUs — multi-pod, near the limit
2048 servers. 16 pods × 1024 GPUs. ~512 leaves, 128 spines, 64 super-spines. You are approaching the single-fabric ECMP limits — hash polarization across 128-way fanout gets ugly fast, and link-failure blast radius starts to matter.
Start evaluating multi-planar here. A single 16K fabric still works, but 32K with the same shape will not.
100K+ GPUs — multi-planar territory
Single CLOS no longer works. 8 parallel planes, each one a full ~16K-GPU fabric. Each NIC index goes to its own plane — NIC 0 to Plane 0, NIC 1 to Plane 1, all the way to NIC 7 to Plane 7. Planes never talk to each other; the collective library knows which NIC is on which plane and steers traffic accordingly. (Cross-reference: see the Multi-Planar pattern in 3.2 Design Options.)
The three scales side by side
The whole ladder on one screen. Numbers assume 400G / 8-GPU servers (the 800G B300 build above is the same shape at double the per-port rate):
| 1,024 GPU | 4,096 GPU | 100K+ GPU | |
|---|---|---|---|
| Topology | 2-tier (leaf + spine) | 2-tier on 51.2T silicon | multi-planar (8 × 3-tier) |
| Servers | 128 | 512 | ~12,500 / plane |
| Rail leaves | 32 (4/rail × 8) | 64 (8/rail × 8) | ~256 / plane |
| Spines | 8 (full 64×400G) | 32 | 128 / plane |
| Super-spine | none | none | 64 / plane |
| Planes | 1 | 1 | 8 |
| Silicon | TH4 / 25.6T | TH5 or Spectrum-4 / 51.2T | TH5 / 51.2T |
| Max hops | 2 | 2 | 4 (cross-pod, same plane) |
| Leaf oversub | 1:2 (32↓ / 16↑) | 1:1 (64↓ / 64↑) | 1:1 |
| ECMP fanout | 8-way | 32-way | 64-way |
| Fabric switches | ~40 | ~96 | ~5,600 (all planes) |
| Cables / optics | ~1,540 | ~8,200 | ~700K |
Spine count isn't "double the previous tier" — it's set by the fact that every leaf uplink must land on a spine port: spines = (leaves × uplinks_per_leaf) / spine_ports. At 4,096 that's (64 × 64) / 128 = 32 spines for a true 1:1 fabric — not 16. Halve it and you've quietly built a 1:2 spine, not the non-blocking fabric you think you have.
2. Switch radix math
The whole BOM falls out of one formula. A leaf has R ports. If R = 64 and each port is 400G:
- 32 ports down (servers) + 32 ports up (spine) = 1:1 oversub at the leaf.
- Pod size for one rail at 1:1 = R/2 servers. For
R = 64: 32 servers per rail × 8 rails = 256 servers / 2048 GPUs per pod. - Spine ports needed per rail = (leaves per rail) × (uplink ports per leaf). Spine radix sets the cap on leaves per rail.
Chip cheat-sheet for the current generation:
| Silicon | Capacity | Port options |
|---|---|---|
| Broadcom Tomahawk 4 | 25.6 Tbps | 64 × 400G or 32 × 800G |
| Broadcom Tomahawk 5 | 51.2 Tbps | 128 × 400G or 64 × 800G |
| NVIDIA Spectrum-4 | 51.2 Tbps | 64 × 800G (OSFP) |
Doubling the silicon doubles the radix, which roughly quadruples the GPUs you can host in a 2-tier pod before you're forced into a third tier.
3. Transceivers — OSFP, AOC, DAC
You will buy more optics than switches. Pick by reach, not by price alone — a $40 DAC that doesn't reach the spine row is a $40 paperweight.
| Type | Reach | Cost | When |
|---|---|---|---|
| DAC (Direct Attach Copper) | ≤ 3 m | Cheapest | Intra-rack: leaf → server in same rack |
| AOC (Active Optical Cable) | ≤ 30 m | Middle | Rack-to-adjacent-rack: leaf → server, or leaf → spine in same row |
| OSFP MMF (Multi-Mode Fiber) | ≤ 100 m | Higher | Across the row: spine → super-spine |
| OSFP SMF (Single-Mode Fiber) | km-class | Highest | Cross-DC, cross-building |
A note on form factor: OSFP and QSFP-DD are both 8-lane 400G/800G modules, mechanically incompatible. NVIDIA Spectrum-4 is OSFP. Many Broadcom Tomahawk designs ship as QSFP-DD. Mixing vendors means an adapter cage or a parallel optic SKU — plan it in the BOM.
4. Cabling for rail-optimized — the labelling scheme
Each server has 8 cables going to 8 different leaves. That is the structural fact you keep in your head. Mislabeling is the day-1 install bug — every cluster build hits it, the only question is how fast you find it.
Standard scheme: <server-id>:<nic-index> → <rail-leaf-id>:<port>. Example: srv-04:nic3 → rail-leaf-3:port-12. Both ends of the cable get the same label, printed twice, heat-shrunk.
Layer a colour code on top of that — Rail 0 = yellow boot, Rail 1 = blue, Rail 2 = green, and so on through 8 distinct colours. The colour catches the gross mis-rack ("why is there a yellow boot on Rail Leaf 3?") before you ever boot a host.
Run a cabling checker script post-install: each host pings its expected rail leaf on every NIC and refuses to boot the workload if NIC 3 lands on Rail 5 instead of Rail 3. Cheap to write, saves a week of NCCL debugging.
Spare 10–20% transceivers from day 1. At 16K GPUs you're racking ~32,000 optics — even at a 0.1% annual failure rate that's 32 modules a year, and they always fail on a Friday.
Skipping the cable-labelling scheme to save time on day 1. You'll spend the same time × 10 finding which NIC went to the wrong rail when the first AllReduce hangs and a thousand GPUs sit idle while you trace fiber under a raised floor. Label before you rack.
5. Design decisions — the cheat-sheet
The recurring forks, with an opinionated answer for each:
| Decision | Call it this way |
|---|---|
| 4,096: super-spine or not? | No super-spine on TH5 / Spectrum-4 — it's a flat 2-tier pod. Add a 3rd tier only if you're stuck on TH4-class silicon and must stitch 1024-GPU pods. |
| Leaf oversub ratio? | 1:2 is fine at 1,024 (intra-rail AllReduce never hits the spine). Go 1:1 at 4,096+ so the spine never bottlenecks AllToAll / MoE. |
| How many spines? | Set by the rule, not by feel: spines = (leaves × uplinks) / spine_ports. 1,024 → 8 full 64-port TH4; 4,096 → 32 × TH5. Add more only for finer ECMP and failure granularity. |
| Redundant spine? | Always — even at the smallest pod. A single spine or single leaf is a SPOF with no recovery path; you can't dual-home a GPU rail NIC. |
| When to go multi-planar? | Start evaluating at 16K. A single fabric at 32K+ hits ECMP hash polarization — plan planes from day one. |
| OSFP vs QSFP-DD? | Standardize on one per build. OSFP for Spectrum-4; QSFP-DD for most Broadcom. Never mix without adapter cages. |
| When does AllReduce cross the spine? | Never, for intra-rail AllReduce. Only AllToAll (MoE expert routing) and cross-pod jobs use the spine. |
| Cable or power first? | Cable the rail leaves and verify with LLDP before powering servers — a mislabeled NIC is cheap to fix before NCCL runs, brutal after. |
💡 What you should remember
| # | Concept | Why it matters | |
|---|---|---|---|
| 1 | 📐 | R/2 servers per rail at 1:1 | The whole BOM rolls up from leaf radix. R=64 → 32 servers per rail × 8 rails = 256 servers / 2048 GPUs per pod at 1:1. |
| 2 | 🏗️ | Radix sets the tier count, not GPU count alone | A 2-tier pod tops out ~8K GPUs at 51.2T (R²/2) — so 4K is still flat, no super-spine. A 3rd tier pushes to ~16K; past that, multi-planar. |
| 3 | 🔌 | DAC inside the rack, AOC across the row, MMF across the hall | Reach picks the optic, not price. |
| 4 | 🏷️ | Label both ends of every cable | 8 cables per server × 2048 servers = 16K chances to get it wrong. |
| 5 | 🎨 | Colour-code by rail | The first-pass visual catch before any host boots. |
| 6 | 📦 | Spare 10–20% optics | Optical failure is continuous, not bursty. Budget for it. |
Next: Master Reference — Interactive Walk-Through → — the whole chapter in one scroll, animated. A different angle on everything you just learned.